以前这个博客刚开始建起来的时候找了很多友情链接,有许多,之后就没再加过别人的链接了,经常偶尔不时的看看当初一起建博客做链接的朋友们,每隔一段时间浏览发现都会碰到个打不开的,暂停的,域名都到期了的等等,现在剩下坚持的就寥寥几个了。本博客建的时间也比较久了,现在还留着的估计也保留着一份情感,不舍得丢弃。看到几个偶尔也还会不时的更新下,由于政策以及其他情况的因素个人站长的时代终究为完结。。。。。
做网站的看来越来越少,坚持者也越来越少
发表回复
以前这个博客刚开始建起来的时候找了很多友情链接,有许多,之后就没再加过别人的链接了,经常偶尔不时的看看当初一起建博客做链接的朋友们,每隔一段时间浏览发现都会碰到个打不开的,暂停的,域名都到期了的等等,现在剩下坚持的就寥寥几个了。本博客建的时间也比较久了,现在还留着的估计也保留着一份情感,不舍得丢弃。看到几个偶尔也还会不时的更新下,由于政策以及其他情况的因素个人站长的时代终究为完结。。。。。
其实做站应该是 04年开始做了,但是那时候只是用的是免费的二级域名和,免费的个人主页空间,真正开始做的时候我是在05年,注册里域名,买了空间,刚刚从有个差网站历史页面的,查询了下自己的站当年的页面,现在看来感觉也是还是那么的熟悉,这么也3、4年走来,坚持下来确实也有点不容易。不知道还能坚持多久,走多久,希望能够还能不断的坚持。
下面是 05年网站某个时段的截图,哈哈。。回忆下,
改查询地址为:http://www.archive.org/web/web.php
显示一个全白的页面需消耗74瓦的功率,而一个全黑的页面却只需59瓦。将这点小差别用在Google上时,你就能发现一件让人惊奇的事情。
Google每天要接受接近2亿条搜索请求,我们假设每次搜索至少在屏幕上显示10秒钟;这就意味着每天Google至少要在不同的电脑上运行55万个小时。让我们再假设每个用户都是全屏显示搜索页面的,那么如果将背景换成黑色将能节约15瓦功率。将这个数据与55万乘起来,黑色版Google每天就能为全球节约8.3兆瓦时电力了。
节约 节约
如果您发现问题,并且感觉在短期内无法修复,您也可以通过在页面当中添加Meta标签,在服务器端强制IE 8使用“IE 7模仿模式”,做法很简单:
a. 针对全站页面: 您可以修改Web服务器(如Apache/IIS/Resin等)的HTTP头信息,在其中增加以下指令: X-UA-Compatible: IE=EmulateIE7。这个是我个人强烈推荐的做法,在您无法进行全站测试的情况下,可以先使用此方式使IE 8的严格模式暂时失效。
b. 针对单独页面:如果您的网站大部分页面在IE 8严格模式下显示正常,只有个别页面出现问题,建议在出现问题的页面的页首,即Head标签内添加以下Meta标签:
<meta http-equiv="X-UA-Compatible" content="IE=EmulateIE7" />。
就是说使得IE8 访问你的网站的时候适用 IE7 的模式,这样简单的多,不需要去改页面。其实一般在IE7 下能正常显示的网页IE8 下也基本能够正常通过。
如果让整个页面都变黑白
自己加到css样式里
body{filter:Gray;}
如果光让图片变黑白
img{filter:Gray;}
如果网站没有使用CSS,可以在网页/模板的HTML代码<head>和</head> 之间插入:
<style>
html{filter:progid:DXImageTransform.Microsoft.BasicImage(grayscale=1);}
</style>
有一些站长的网站可能使用这个css 不能生效,是因为网站没有使用最新的网页标准协议
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
请将网页最头部的<html>替换为以上代码。
有一些网站FLASH动画的颜色不能被CSS滤镜控制,可以在FLASH代码的<object …>和</object>之间插入:
<param value="false" name="menu"/>
<param value="opaque" name="wmode"/>
最简单的把页面变成灰色的代码是在head 之间加
<style type="text/css">
html {
FILTER: gray
}
</style>
现在虽然来说采集站越来越难做了,但是还是有很多人在采集,毕竟不需要很多精力就可以做一个内容丰富的站出来了。防采集现在虽然有很多方法,但是也没有有效方法,虽然有的能防止采集但是弊端也有很多,下面对几个放采集的方法做个总结,可能不是很全、
1。防采集就是用JS调用,列表用JS调用,或者文章的开头或者结尾替换成JS文件。但是这样对于有些禁用JS的浏览器访问,更不根本访问不到内容,或者访问内容不全。
2. 采用限制刷新次数,就是同一个IP在规定时间内刷新几次,有服务器上限制的,也有程序限制的,但是对于搜索的蜘蛛有很大影响。
3. 还有就是采用多套模板,像我采集的时候碰到多套模板就是先一个规则采集好,再找到另外一个模板的规则,再采一篇。。。。。
4、还有就是内容中增加随机字符,但是这个效果不是很大,可以过滤,除非要N多的信息,但是可以直接过滤掉网站名称相关的词,也网站地址相关的,同样可以处理。
5. 其实现在觉得一个最好的方法就是内容的部分文字生成图片,再打上图片。碰到这种基本人家看不上了、。、、
其实也没花多少时间,就是这样放着好久了,这里弄一点,那里弄一点,今天去了,湖州,现在差不多英文版已经完成。。。中文版也好了,还有就是等日文拿到手,文字套一下就可以了
网站雷达 (Radar Website Monitor)是一款多线程的网站监控工具,能监视HTTP, SMTP, POP3, FTP, DNS, TCP和数据库等多种internet网络服务,一旦有问题被检测到或有错误发生它会提出通报,也能分析服务器响应时间并向你发送报告。
原文件是用Radar Website Monitor 4.6英文绿色版,汉化的。
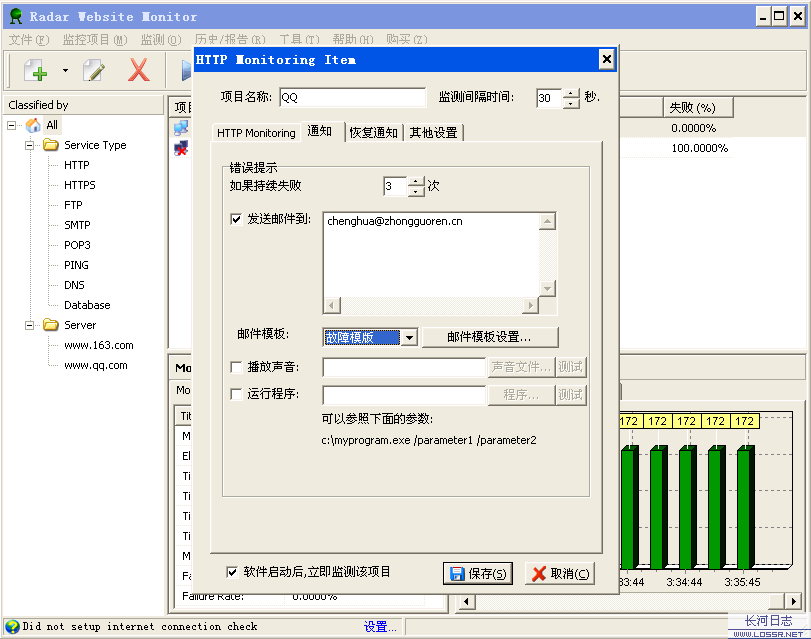
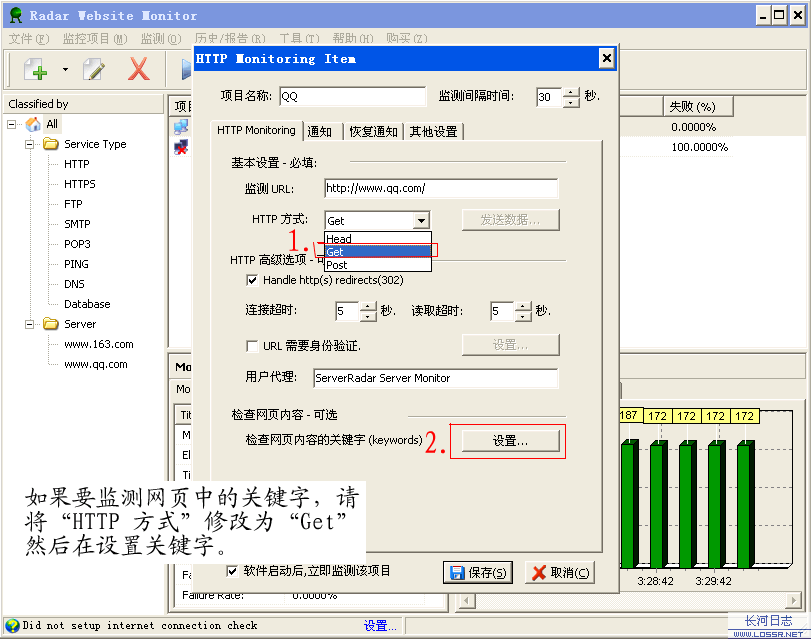
如果要监测网页中的关键字,请将“HTTP 方式”修改为“Get”
然后在设置关键字。
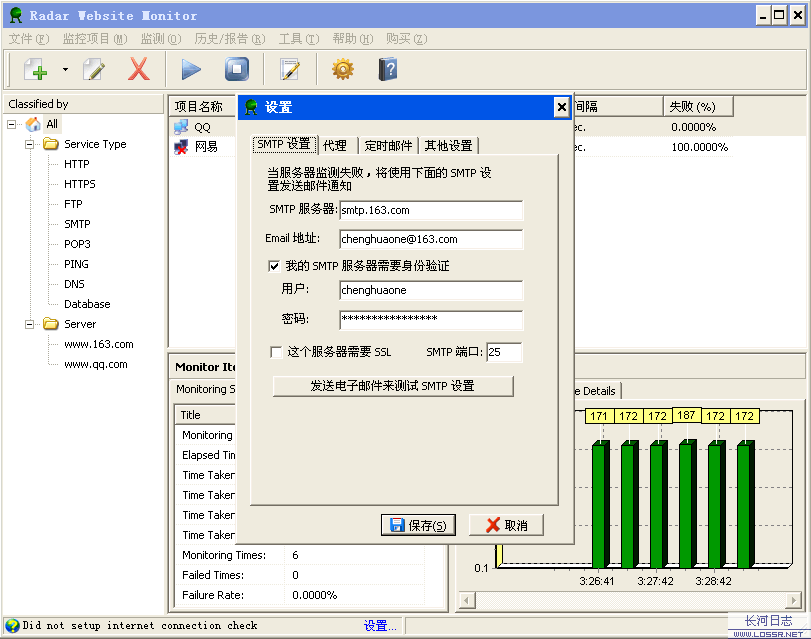
你也可以在网上找些免费的短信接口,网页地址放在“运行程序”栏,当你的服务器出问题后,可以及时通过手机短信帖子你。
下载地址:
http://www.maqie.com/download/Radar Website Monitor.rar
转自:http://www.im286.com/viewthread.php?tid=2144125&extra=&page=1
{kind=link}